2020年オープンキャンパス(青木・伊藤(康)研究室)

本研究室では,主に画像処理の研究をしていますが,画像処理以外の研究も行っています.その1つがバイオインフォマティクスの研究です.バイオインフォマティクスとは,生命科学と情報科学の融合分野です.ゲノム解析などが有名です.その中に,アプタマーと呼ばれる人工核酸を設計する研究があります.アプタマーは,特定のタンパク質に結合する塩基配列であり,その特性を利用してバイオ医薬品や分子センシングなどに応用されます.ここでは,膨大な核酸配列の中からアプタマーを探し出す研究について説明します.
特定の標的分子に結合する塩基配列は未知であるため,大量の核酸の中から化学実験により見つけ出すしかありません.一般的にはSystematic Evolution of Ligands by EXponential enrichment (SELEX) と呼ばれる方法が用いられています.最近では,次世代シーケンシング (Next-Generation Sequencing:NGS) と組み合わせた HT-SELEXが用いられています.図1は,HT-SELEXの手順を図示したものです.HT-SELEXの6ステップは以下の通りです.
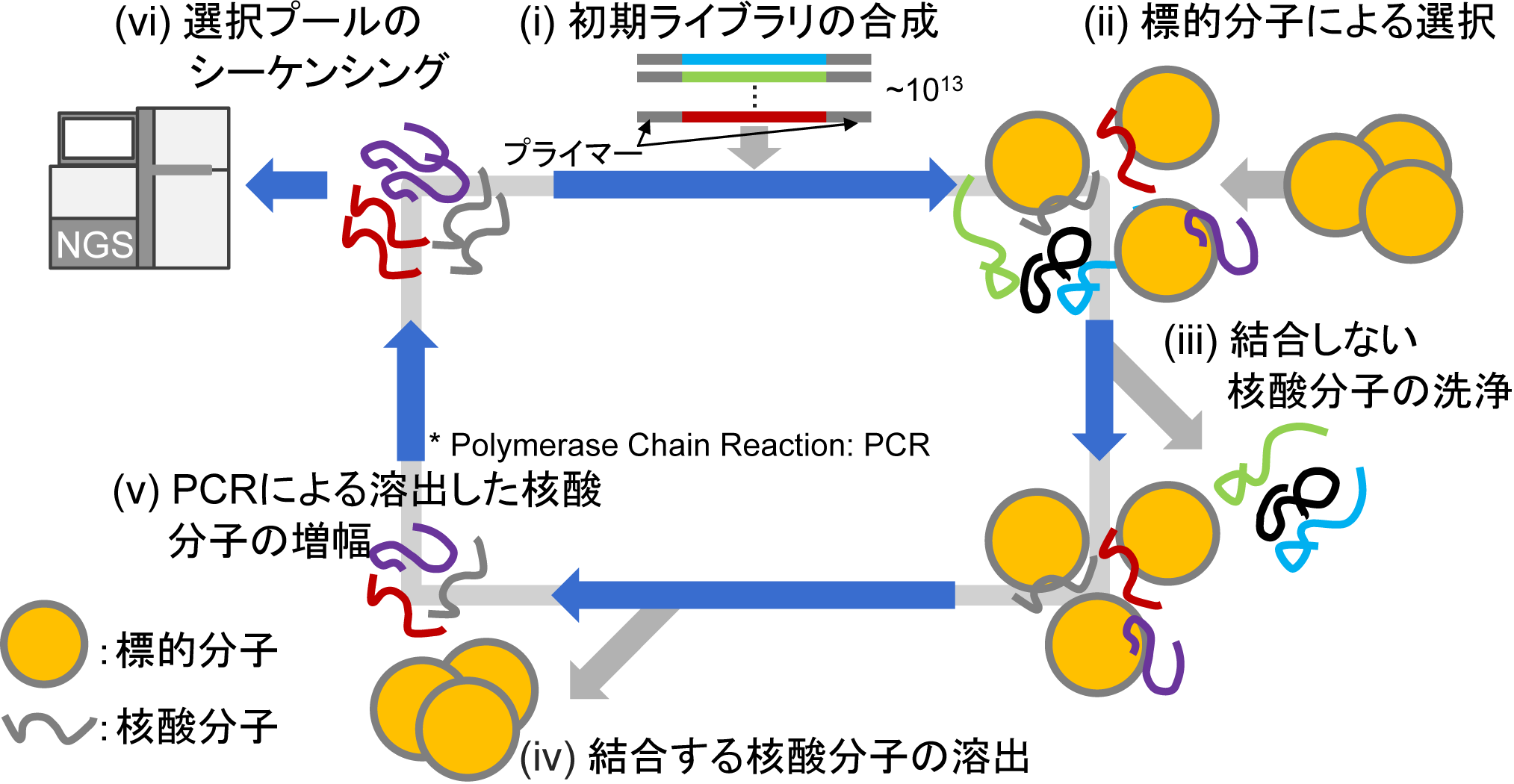
HT-SELEXで得られた大量のシーケンスデータからアプタマーを見つけるためには,全データに対して実験的に評価する必要があります.費用と時間の面から非現実的です.そこで,標的分子との親和性が高い配列を計算機にて見つけ出すことができれば,費用と時間を大幅に節約することができます.そこで,本研究室では,アプタマーの選別を支援するためのクラスタリング手法を提案しています.クラスタリングとは,特徴が似ているものをグループとしてまとめるような操作です.私たちが提案している Fast String-Based Clustering (FSBC) では,統計的なスコアを利用することで高速かつ高精度に大量のシーケンスデータをクラスタに分けることができます.以前は膨大な時間がかかっていましたが,FSBCでは1分程度でアプタマーの候補を見つけることができます.詳細は,文献 [1] を参照してください.
簡単ではありますが,本研究室で取り組んでいるバイオインフォマティクスの研究について紹介しました.まだはじめたばかりの新しいテーマではありますが,NECソリューションイノベータ株式会社バイオラボと共同で,アプタマー候補を高速に見つけ出すクラスタリング手法やアプタマー配列の小型化手法など,アプタマーの実用化を推進するための手法に関する研究を進めています.